
논문 - SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFs, Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille
1. Motivations/Problems
DCNN은 image classification과 object detection에서 좋은 성능을 보여준다. 하지만 Semantic segmentation에 DCNN을 적용하는데 두 가지 기술적 한계가 존재한다.
1. Signal downsampling: 기존 DCNN의 각 계층(max-pooling, downsampling/stride)을 지나면서 feature resolution의 감소한다.
(CNN의 네트워크는 네트워크가 깊어질수록 feature들의 크기가 작아진다.)
2. Spatial invariance: DCNN의 invariance 특성은 공간의 추상적인 정보를 필요로하는 image classification에서는 장점이었지만, 정확한 localization을 요구하는 semantic segmentation에서는 spatiacl accuracy를 제한한다.
2. Key ideas
본 논문에서는 위의 두 문제를 해결하기 위한 방법으로
1. atrous algorithm(hole algorithm) 적용
2. DCNN-based pixel-level classifier와 CRF 결합
새로운 모델인 DCNN과 fully-connected CRF(conditional random field)를 결합한 DeepLab을 제안한다.
이 모델과 다른 모델의 큰 차이점은 pixe-level CRFs와 DCNn-based unary term의 조합이다. 모든 pixel을 CRF 노드로 취급하고, long range dependency를 활용하고, CRF inference를 사용하여 DCNN 기반 비용 함수를 직접 최적화한다.
DeepLab의 장점
1) sematically accurate prediction
2) 타 최신 모델과 비교해 보다 detailed segmentation map를 생성
3) 효율적인 computing
3. Network Design
해당 모델은 pretrain된 VGG-16를 dense feature extractor로 사용했다.
1. Controlling receptive field
기존 DCNN 기반 image recognition 방식은 Imagenet large-scale task에서 pretrainpretrain 된 네트워크를 사용하기 때문에 receptive field의 크기가 크다. VGG-16의 CONV 계층을FC 계층으로 변환해 사용하면, 4096개 7x7 크기의 필터를 가지게 되어 bottleneck이 된다.
dense score 컴퓨팅을 효율적으로 하기 위해서, 네트워크의 receptive filed의 크기를 명시적으로 제어하기 위해 "hole algorithm"을 적용했다.
VGG-16의 FC 계층을 convoluiton 계층으로 바꾸고, 마지막 max-pooling layer 2개를 제거한다. 그리고 "hole algorithm"을 적용해서 넓은 receptive field를 볼 수 있게 했다.
각 input stride를 2 pixel, 4 pixel을 사용해서 feature map을 sparsesparse 하게 샘플링하여 문제를 해결했다.
|
hole algorithm(atrous altorithm)  (a) 기본적인 convolution (kernel=3) |

본 논문에서는 atrous 알고리즘을 Caffe 프레임워크 내 im2col 함수에 feature map을 sparsesparse 하게 샘플링하는 옵션을 추가해 구현했다.
(이 방법은 generally 응용 가능하며, 근사치를 도입하지 않고도 모든 target subsampling rate에서 효율적으로 dense CNN feature map을 계산하게 해 준다.)
Testing에서 bilinear intepolation(이중 선형 보간법)을 사용하여 DeeLab 모델의 출력 resolution을 8배 증가시켜 original image resolution의 class score map을 만든다.

2. Detailed boundary recovery: Fully-connected CRFs and Multi-scale prediction
DCNN score map은 이미지에서 객체의 존재와 대략적 위치를 안정적으로 예측하지만, 정확한 윤곽을 예측하는 데는 적합하지 않다는 단점이 있다. CNN을 사용하면 classification accuracy와 localization accuracy 사이 절충이 필요하다.
여러 개의 max-pooling layer를 사용하는 DCNN이 classifiacation task에 적합하지만, 증가하는 invariance와 큰 receptive field는 최종 출력의 score에서 위치를 추론하는 문제를 어렵게 만든다.
본 논문은 ‘DCNN의 인식 능력(recognition capacity)’과 ‘fully-connected CRFs의 세분화된 지역화 능력(localization capacity)’을 결합해 새로운 해결방안을 추구했다. 그리고 해당 모델이 기존 방법을 뛰어넘는 수준으로 성공했음을 보여준다. (localization challenge를 해결, 정확한 semantic segmentation 결과를 생성, 뛰어난 객체 경계 복구 성능)
Fully-connected CRFs for accurate localization
전통적으로, short-range CRFs는 segmentation map의 노이즈를 매끄럽게 하기 위해 사용된다.
하지만 DCNN의 max-pooling과 upsampling을 수행하면서 1/8 크기로 작하진 결과를 bilinear intepolation으로 기존 크기로 확대하기 때문에, score map은 충분히 매끄럽다.
따라서 우리의 목표인 객체 경계 복구에 short-range CRFs를 사용하는 것은 적절치 않다.
local-range CRFs과 함께 contrast-sensitive potential을 사용하면 localization을 잠재적으로 개설할 수 있지만 여전히 얇은 구조를 놓칠 수 있으며, 고비용의 이산 최적화 문제(discrete optimization problem)를 해결해야 한다.
이런 short-range CRFs의 한계를 극복하기 위해, Krahenbuhl & Koltun(2011)의 fully-connected CRFs 모델을 시스템에 결합했다.
fully-connected CRFs의 에너지 함수 (타 블로그의 설명을 빌려옴)

- x : 해당 pixel의 label
- i, j : 픽셀의 위치
- unary term : DCNN을 통해 계산된 픽셀 i에서의 label 할당 확률
- pairwise term : 픽셀 간 거리가 얼마가 되든, 픽셀 i와 j의 각 쌍에 대해 pairwise term이 존재한다. 즉 모델의 factor graph가 fully-connected 되어있다.
본 논문에서는 bilateral position과 color terms을 채택한다.

위 CRF의 수식은 2개의 가우시안 커널로 구성된다. 알파, 베타, 감마를 통해서 scale을 조정한다.
1) 첫 번째 커널은 비슷한 위치 비슷한 색상을 갖는 픽셀들에 대하여 비슷한 label이 붙게 한다. (pixel position&color intensity 사용)
2) 두 번째 커널은 픽셀의 근접도에 따라 smooth 수준을 결정한다. (pixel position만 사용)
이것을 고속으로 처리하기 위해, Philipp Krahenbuhl 방식을 사용하게 되면 feature space에서는 Gaussian convolution으로 표현을 할 수 있게 되어 고속 연산이 가능하다.
이 모델은 근사 확률 추론(approximate probability inference)을 효율적으로 처리한다. fully-decompasable mean field approximation 방법을 적용하여 message passing을 사용한 iteration을 적용하면 효율적으로 fully-connected CRF를 수행할 수 있다.
3 MULTI-SCALE PREDICTION
DeepLab은 추가적으로 boundary localization 정확도를 높이기 위해 multi-scale prediction도 시도했다.
input image와 첫 번째 4개의 max-pooling layer의 output을 메인 네트워크의 마지막 layer의 feature map에 연결된 2-layer MLP에 연결했다. softmax 계층에 입력되는 총 feature map은 5x128 = 540 채널로 강화된다.
* 2-layer MLP
- 첫 번째 layer: 128 3x3 convolutional layer
- 두 번째 layer: 128 1x1 convolutional layer
fine-resolution layer에 MLP를 추가할 경우 localization 성능이 향상된다.
DeepLab V1 Design 정리
DCNN의 출력 coarse score map을 bi-linear interpolation으로 upsampling 해서 기존 이미지의 크기로 확대한다. 이후 full-connected CRF로 결과를 정제해서 정확도를 높인다.
1. intermediate layer에 multi scale feature 사용
2. fully-connected CRF로 segmentatin result를 정제(refinement)
3. large FOV(field of view, input stride를 증가시킴) 계산 속도 증가
4. Performance
Evaluation
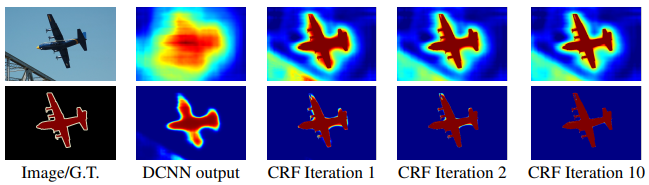
DeepLab과 fully-connected CRFs를 통합한 모델의 성능이 크게 향상한다(기존 DeepLab보다 4% 증가). 복잡한 객체 경계를 정확히 포착한다.

multi-scale features
DeepLab의 intermediate layer에 multi-scale feature를 추가한 모델의 성능이 1.5% 향상했다.
여기에 추가로 fully-connected CRFs를 통합하면 성능이 약 4% 향상한다.
Find of view

‘atrous algorithm’을 사용해서 입력 stride를 조절하면서 모델의 FOV(field of view)를 임의로 조정해서 해상도 저하 문제를 해결하고 연산 시간을 절감했다.
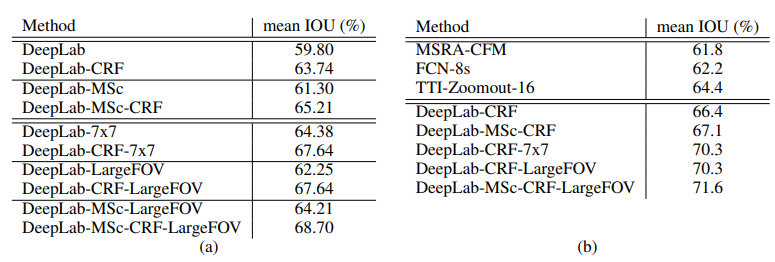
DeepLab-CRF로 다양한 input stride와 커널 사이즈를 실험했을 때, ‘DeepLab-CRF-7x7’은 67.64% 성능을 보이지만 느리다는 단점을 가진다.
- 해당 모델에서 커널 사이즈를 4x4로 줄여 모델 속도를 초당 2.9 이미지로 개선했다(DeepLab-CRF).
- FOV를 input stride=8으로 조절한 DeepLab-CRF-4x4이 DeepLab-CRF 모델보다 좋은 성능을 보인다.
- 커널 사이즈 3x3, input stride=12 로 설정한 DeepLab-CRF-LargeFOV는 DeepLab-CRF-7x7와 동일한 성능을 보였다. 하지만 DeepLab-CRF-LargeFOV의 실행 속도가 3.36배 빠르고 파라미터도 20.5M로 매우 적어 훨씬 효율적이다.
최종적으로, 논문의 실험을 통해 DeepLab에 multi-scale feature와 large-FOV를 활용해서 복잡한 객체 경계를 빠르고 정확히 예측해낼 수 있음을 확인했다.
Test and results
DeepLab-CRF 및 DeepLab-MSC-CRF 모델은 각각 평균 IOU 66.4%, 67.1% 성능을 보인다. 이는 다른 최신 모델과 비교해 큰 차이를 보여준다. 또한 모델 FOV를 증가시킨 DeepLab-CRF-LargeFOV 는 DeepLab-CRF-7x7과 동일한 성능을 내면서 동시에 train 속도는 더 빠르다는 장점을 가진다.
multi-scale feature와 large-FOV를 모두 사용한 DeepLab-MSC-CRF-LargeFOV는 best 성능을 보인다.
[참고]
논문 - SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFs, Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille
m.blog.naver.com/laonple/221017461464
[Part Ⅶ. Semantic Segmentation] 6. DeepLab [2] - 라온피플 머신러닝 아카데미 -
라온피플 머신러닝 아카데미 [Part Ⅶ. Semantic Segmentation]6. DeepLab [2] Semantic Segmentati...
blog.naver.com
[논문] DeepLab v2
논문 : https://arxiv.org/pdf/1606.00915.pdf semantic segmentation에 관련된 또 다른 논문이다. Deeplearning의 CNN 네트워크는 영상처리의 대부분의 문제에서 그 효과를 발휘하고 있다. 이전에 말했듯이 class..
dogfoottech.tistory.com
'CS > 논문 리뷰' 카테고리의 다른 글
| [논문리뷰] UNet++: A Nested U-Net Architecture for Medical Image Segmentation (0) | 2021.09.16 |
|---|---|
| [논문 리뷰] Mask R-CNN (0) | 2021.04.18 |
| [논문 리뷰]U-Net - Convolutional Networks for Biomedical Image Segmentation (0) | 2021.04.08 |
| [논문 리뷰] Inception - Going deeper with convolutions (0) | 2021.03.18 |