
Overview
- Unsupervised Learning
- Generative models: PixelRNN and CNN, VAE, GAN
Unsupervised Learning (비지도 학습)
label 없이 학습 데이터만으로 데이터에 숨어있는 구조를 학습하는 방법
ex) Clustering, dimensionality reduction, feature learning(Autoencoders), density estimation
| Supervised learning | Unsupervised learning | |
| Data | x: data, y: label | just data |
| Goal | x->y로 맵핑하는 함수를 학습 | 데이터에 숨겨진 구조를 학습 |
| Example | classification, regression, object detection ... | clustering, feature learning, dimentionality reduction ... |
Generative Models
training data와 같은 분포에서 새로운 sample을 생성하는 model
즉, model's prob(x)가 최대한 data's prob(x)와 가깝게 만드는 것이 목표이다.
Generative model은 density estimation을 다루는데 density의 정의에 따라 두 개로 나뉜다.
- Explicit density estimation: P_model의 분포를 명시적으로 정의 //PixelRNN/CNN, VAE
- Implicit density estimation: P_model의 분포를 정의하지 않음 //GAN
(P_model에서 샘플을 만들어내도록 학습시키는 것은 동일)

다양한 Generative model 중에서 PixelRNN/CNN, VAE, GAN을 자세히 살펴본다.
PixelRNN and PixelCNN
PixelRNN
- Fully visible brief network의 일종
- explicit density model
| * Fully visible brief network? 확률의 chain rule을 사용해서 n-dimensional vector x를 1-dimensional probability distribution으로 decompose하는 방법 (참고: https://kakalabblog.wordpress.com/2017/07/27/gan-tutorial-2016/) |

- Chain rule을 사용해 P(x)를 1차원 분포들 간의 곱(product of 1-d distributions) 분해한다.
각각의 픽셀 x_i에 대해 P(x_i|conditions) 정의 가능 (conditions = 이전 모든 픽셀, x_1 ~ x_(i-1))
- training data의 likelihood (p(x))를 최대화하도록 모델을 학습시킨다
PixelRNN의 이미지 생성 과정
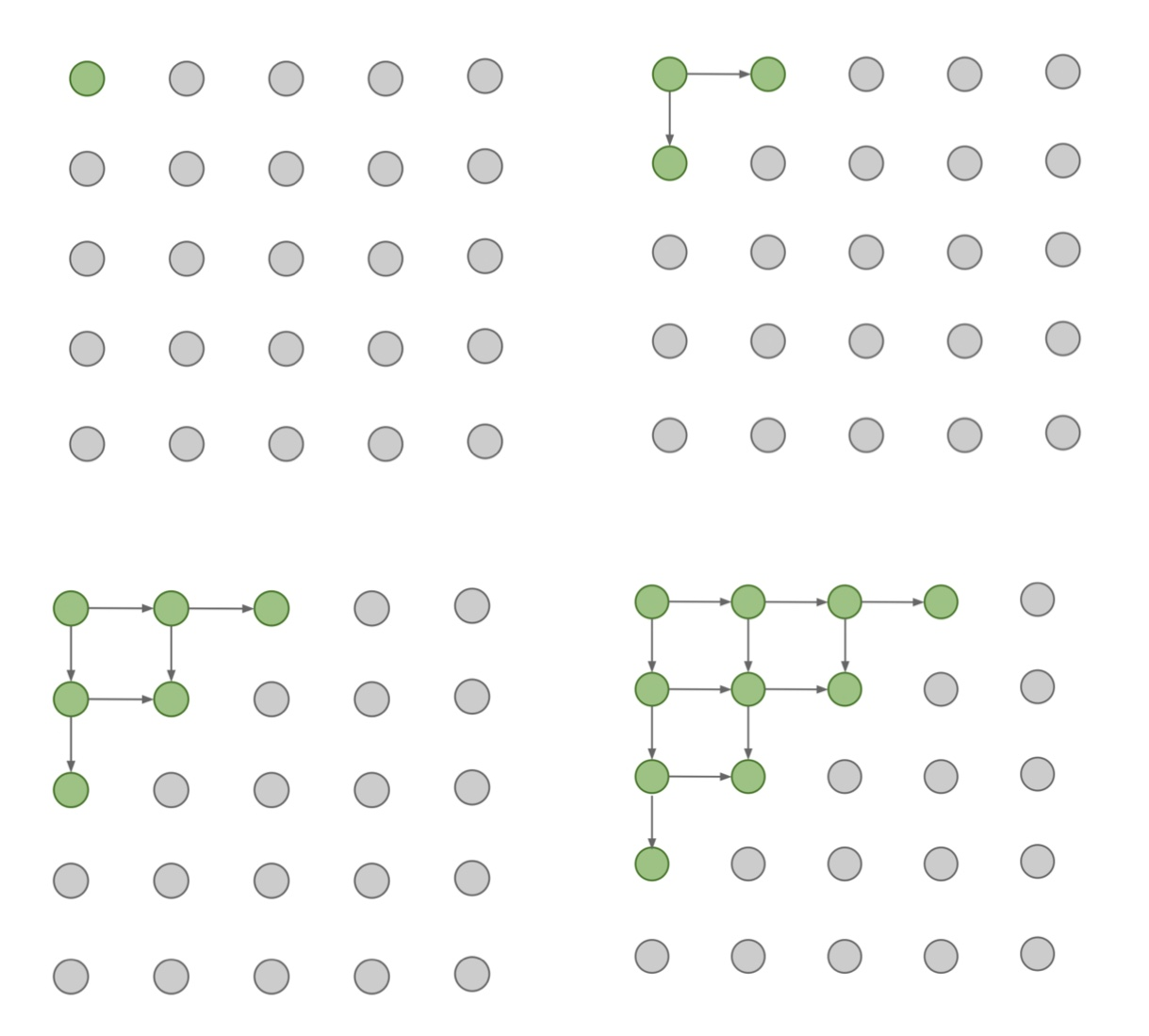
- 먼저 이미지의 좌상단 코너의 픽셀부터 생성을 시작한다.
- 화살표로 표시된 연결성을 기반으로 대각선 방향으로 내려가면서 순차적으로 픽셀을 생성한다. RNN을 사용해 이전 픽셀들과의 dependency를 모델링한다. (*앞선 수식에 나오는 condition을 의미)
PixelRNN의 단점
- sequential generation model로 매우 느리다
한 이미지를 생성하기 위해 모든 픽셀이 생성될 때까지 반복적으로 네트워크를 수행해야 한다.
PixelCNN
좌상단 코너부터 이미지를 sequential 하게 생성하는 것은 PixelRNN과 동일하다.
RNN과 차이점은 이미 생성된 픽셀들 중 일부만 dependency를 CNN으로 모델링한다. (*context region에 포함되는 픽셀만 사용해서 현재 픽셀의 likelihood를 계산)
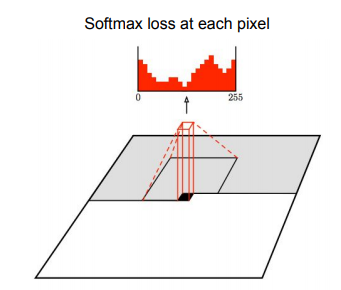
PixelCNN의 단점
- sequntial generation이기 때문에 여전히 느리다
Training time에는 context redion의 픽셀 값들을 이미 알고 있기 때문에 계산을 병렬화할 수 있어 빠르지만, Generation time에서 이미지를 생성하기 위해서 여전히 코너에서 순차적으로 픽셀을 생성해야 하기 때문에 여전히 느리다는 문제가 있다.
PixelRNN/CNN은 tractable density function을 미리 정의하여 train data의 likelihood를 직접(directly) 최적화하는 방식이었다. 반면 VAE는 intractable density function을 정의한다.
VAE
VAE의 기본이되는 autoencoder를 먼저 살펴본다.
Autoencoders
unlabeled training data로부터 lower-dimensional feature representation을 학습하기 위한 unsupervised approach
- Encoder: 입력 데이터 x를 lower-dimansional feature z로 인코딩
- Decoder: feature를 기반으로 원본 데이터와 유사하도록 이미지를 재구성
(Encoder를 학습하기 위해 Decoder가 있다고 이해)
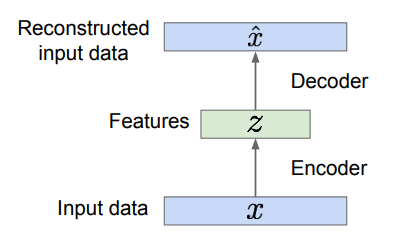
- 입력 데이터 x를 encoder에 통과시켜 z를 얻는다. (e.g. conv net)
- encoder의 출력 z를 decoder에 통과시켜 원본 데이터를 복원한다. (e.g. upconv net)
z는 x보다 작기 때문에 encoder로 dimensionality reduction 효과를 얻을 수 있다.
Q) dimentionality reduction의 이유?
feature z가 training data의 중요한 factor만 학습하도록 하기 위해서 차원을 축소하게 된다.
*laten variable z: 잠재 변수, 각 차원에 학습 데이터의 interpretable factors of variation을 담고 있음 (e.g. 웃음의 정도, 머리 위치 ...)
Training Autoencoder

L2 loss function을 사용해 feature가 최대한 원본 데이터로 재구성될 수 있게 encoder와 decoder를 학습한다.
- L2 loss 의미 = 복원한 이미지의 픽셀 값이 원본 이미지의 픽셀 값과 같아지는 방향으로 학습
- loss 계산에 추가적인 label이 필요 없다. (unsupervised learning)
Train for final task
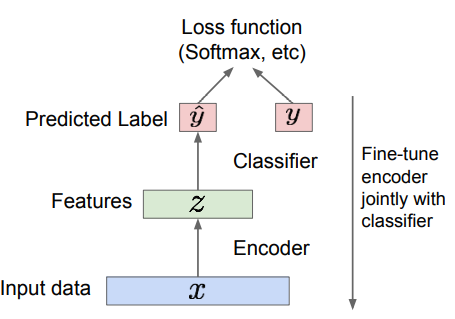
학습이 끝나면 decoder는 버리고 ecoder만 가져와 downstream task에 맞게 학습시킨다.
- 학습시킨 Encoder를 supervised learning model을 초기화하는 데 사용할 수 있다.
Autoencoder는 unlabeled data에서 양질의 general feature representation을 학습할 수 있는 장점을 가진다. 이렇게 학습시킨 feature representation을 데이터가 많지 않은 supervised learning model의 초기 가중치로 이용할 수 있다.
예를 들어, classification task에 Autoencoder를 사용할 경우 encoder로 classifier를 초기화할 수 있다. classifier와 encoder를 결합해 해당 task에 맞게 다시 학습시킨다.
Autoencoder의 장점
- Autoencoder can reconstruct data and can learn features to initailize a supervised model
Autoencoder는 원본 데이터를 재구성하고, 이를 위해 학습 데이터의 feature representation을 학습한다. 여기서 잠재 변수인 z, feature가 training data의 variation factor를 포착한다.
이런 autoencoder 특성을 이용해 새로운 이미지를 생성할 수 없을까라는 아이디어에서 VAE가 나왔다.
Variational Autoencoders (VAE)
(내용이 어려워 잘 이해하지 못했다. ㅠㅜ)
- autoencoder의 변형
- Generative model: explicit density
VAE는 AE와 다르게 laten variable z로부터 이미지 x를 생성하는 모델이다. (Autoencoder의 decoder의 역할과 유사)

true parameter 'theta'를 추정하려 한다.
- prior p(z): 가우시안
- p(x|z): Decoder network(Neural network) //이미지를 생성해야 하기 때문에 complex
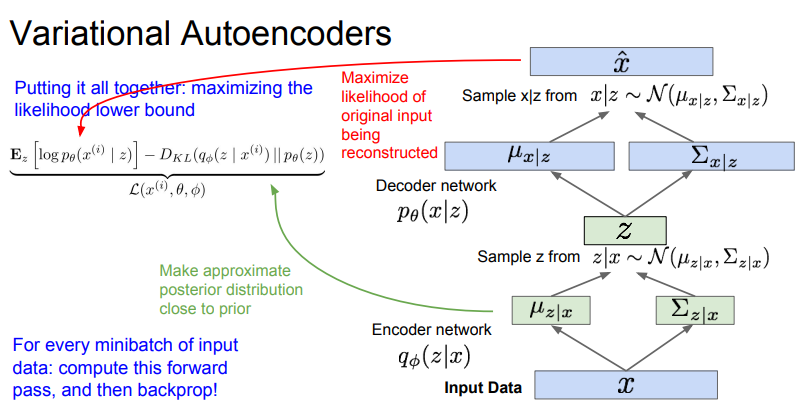
VAE 구조

- Encoder: x를 입력으로 받아 z space 상에서 확률 분포를 만든다 (가우시안)
- data dependent gaussian 분포로부터 z를 샘플링한다
- 샘플링된 z를 decoder의 입력으로 넣어 x space 상의 gaussian or Bernoulli distribution을 얻는다.
- 이렇게 얻은 분포에서 x를 샘플링한다.
학습이 되고 나서 laten variable z는 data의 의미있는 representation을 포함하게 된다.
VAE의 Likelihood

- Decoder Network term: Reconstruction
original input data와 유사하게 이미지를 재구성하는 역할
- 첫번째 KL term
근사된 posterior의 분포가 얼마나 normal distribution과 가까운지에 대한 척도
- 두번째 KL term: 무조건 0보다 크다
첫번째. 두번째 항은 모두 계산이 가능하고 마지막 항은 무조건 0보다 크거나 같기 때문에 VAE의 likelihood의 lower bound를 계산할 수 있다.
After train: Generating Image
이렇게 VAE가 laten vector z를 학습하면 새로운 이미지를 생성할 수 있게 된다.
GAN
model의 density를 명시하지 않고, training data의 분포에서 샘플링만 잘하도록 모델을 만들자는 아이디어
- implicit density model
- game-theoretic approach: 2-player game 방식으로 분포를 학습
GAN 모델은 discriminator와 generator network로 구성된다.
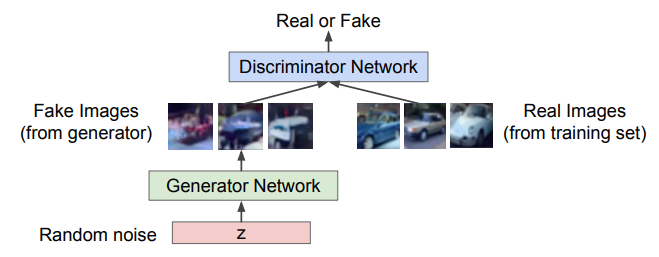
- Generator: random noise에서 fake image를 만들어서 discriminator를 속이는 것이 목표
- Discriminator: 입력 이미지가 'real' 또는 'fake'인지 구별하는 것이 목표 (실제 train data와 generator가 만든 이미지를 구별해내는 것)
Training GANs: 2-player game
discriminator가 잘 학습돼서 real, fake을 잘 구분할 수 있다면 generator는 discriminator를 속이기 위해서 더 사실에 가까운 이미지를 만들어내도록 학습할 것이다. 이를 통해 좋은 generator model을 얻을 수 있다.

두 네트워크를 minmax game 형태로 같이 학습시킨다.
- Discriminator: objective func을 최대화, D(x)가 1에 가까워지도록, D(G(x))가 0에 가까워지도록 optimize
- Generator: objective func을 최소화, 1-D(G(x))가 0에 가까워지도록 optimize
*1-D(G(x)) 가 0에 가깝다 = discriminator가 가짜 이미지를 진짜로 분류하고 있음 = generator가 이미지를 realistic 하게 생성하고 있다
이를 수식으로 표현하면

하지만 실제로 generator의 objectibe func은 잘 동작하지 않는다.
generator가 생성한 샘플이 좋지 않을 때의 gradient가 상대적으로 평평해 네트워크가 잘 학습되지 않는 문제가 발생한다. (좌측으로 갈수록 기울기가 평평하다)
이를 해결하기 위해 discriminator가 정답을 맞힐 확률을 최소화하는 대신 discriminator가 틀릴 확률을 최대화하도록 objective func을 변경한다.

After Train: Generating Image
모델 학습이 끝나면 generator를 사용해서 새로운 fake image를 생성한다.
Interpretable Vector Math
laten variable z는 vector로 벡터 연산이 가능하다.

정리
| PixelRNN/CNN | VAE | GAN |
| - explicit density model - optimize exact likelihood of data 장점 - good sample 단점 - inefficient sequential generation |
- explicit density model - optimize variational lower bound on likelihood 장점 - useful feature representation 단점 - sample quality not the best |
- implicit density model - 2-player game 장점 - SOTA 단점 - 학습이 까다로움 (두 개의 네트워크의 균형을 이루면서 학습을 해야하기 때문에) - objective func을 directly optimize 하지 않음 |
Reference
'CS > CS231N (2017)' 카테고리의 다른 글
| [cs231n] lec14 - Reinforcement Learning (0) | 2021.09.16 |
|---|---|
| [cs231n] Lec12 - Visualizing and Understanding (0) | 2021.08.31 |